超級計(jì)算機(jī)作為高性能計(jì)算的代表,其編程方式與普通計(jì)算機(jī)有著顯著差異。開發(fā)人員需要深入理解超級計(jì)算機(jī)的軟硬件架構(gòu),并掌握專門的編程技術(shù)和工具。以下從軟硬件開發(fā)的角度,系統(tǒng)介紹超級計(jì)算機(jī)編程的關(guān)鍵要點(diǎn)。
一、硬件架構(gòu)理解是編程基礎(chǔ)
超級計(jì)算機(jī)通常采用大規(guī)模并行架構(gòu),包括:
- 節(jié)點(diǎn)集群結(jié)構(gòu):由成百上千個計(jì)算節(jié)點(diǎn)組成,每個節(jié)點(diǎn)可視為獨(dú)立計(jì)算機(jī)
- 高速互聯(lián)網(wǎng)絡(luò):如InfiniBand、Omni-Path等專用網(wǎng)絡(luò)技術(shù)
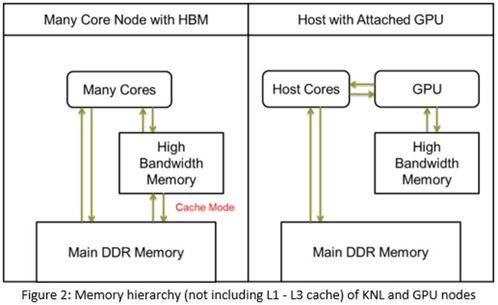
- 分層存儲系統(tǒng):包含內(nèi)存、SSD、并行文件系統(tǒng)等多級存儲
- 加速器設(shè)備:GPU、FPGA等專用計(jì)算加速硬件
開發(fā)人員必須了解這些硬件特性,才能編寫出充分利用硬件性能的程序。
二、并行編程模型和方法
- 分布式內(nèi)存編程:
- MPI(Message Passing Interface)是最主要的編程模型
- 實(shí)現(xiàn)節(jié)點(diǎn)間通信和數(shù)據(jù)交換
- 需要仔細(xì)設(shè)計(jì)通信模式,避免性能瓶頸
- 共享內(nèi)存編程:
- OpenMP適用于單節(jié)點(diǎn)內(nèi)多核并行
- 通過指令指導(dǎo)編譯器生成并行代碼
- 混合編程模型:
- MPI+OpenMP組合使用
- MPI負(fù)責(zé)節(jié)點(diǎn)間并行,OpenMP處理節(jié)點(diǎn)內(nèi)并行
三、GPU和加速器編程
對于配備GPU的超級計(jì)算機(jī):
- CUDA編程:NVIDIA GPU專用編程框架
- OpenACC:指令式并行編程模型
- HIP:AMD GPU編程框架
- SYCL/DPC++:跨廠商異構(gòu)編程標(biāo)準(zhǔn)
四、軟件開發(fā)工具和生態(tài)環(huán)境
- 編譯器:Intel編譯器、GCC、NVCC等專用編譯器
- 性能分析工具:Intel VTune、NVIDIA Nsight、TAU等
- 調(diào)試工具:TotalView、DDT等并行調(diào)試器
- 作業(yè)調(diào)度系統(tǒng):Slurm、PBS等作業(yè)管理系統(tǒng)
五、優(yōu)化策略和最佳實(shí)踐
- 負(fù)載均衡:確保計(jì)算任務(wù)均勻分配到所有處理器
- 數(shù)據(jù)局部性:優(yōu)化數(shù)據(jù)訪問模式,減少通信開銷
- 向量化優(yōu)化:利用SIMD指令提升單指令多數(shù)據(jù)處理能力
- I/O優(yōu)化:采用并行I/O技術(shù),避免存儲瓶頸
六、領(lǐng)域特定編程框架
根據(jù)應(yīng)用領(lǐng)域選擇相應(yīng)框架:
- 科學(xué)計(jì)算:PETSc、Trilinos等數(shù)學(xué)庫
- 人工智能:TensorFlow、PyTorch的分布式版本
- 大數(shù)據(jù):Spark on HPC環(huán)境
- 分子動力學(xué):GROMACS、NAMD等專用軟件
七、持續(xù)學(xué)習(xí)和技能提升
超級計(jì)算機(jī)技術(shù)快速發(fā)展,開發(fā)人員需要:
- 關(guān)注新型架構(gòu)發(fā)展(如量子計(jì)算、神經(jīng)形態(tài)計(jì)算)
- 學(xué)習(xí)新興編程模型(如MPI-4、OneAPI)
- 參與HPC社區(qū)和培訓(xùn)項(xiàng)目
- 在實(shí)際項(xiàng)目中積累調(diào)優(yōu)經(jīng)驗(yàn)
超級計(jì)算機(jī)編程是一個復(fù)雜的系統(tǒng)工程,需要開發(fā)人員在硬件架構(gòu)、并行編程、性能優(yōu)化等多個維度具備專業(yè)能力。通過系統(tǒng)學(xué)習(xí)和實(shí)踐,開發(fā)人員能夠充分發(fā)揮超級計(jì)算機(jī)的強(qiáng)大計(jì)算能力,推動科學(xué)研究和工程應(yīng)用的發(fā)展。